

どんな記事
EDINETという金融庁が運用している企業情報の開示システムから、「PER、ROE、配当」などの財務データを取得してスクリーニングをする方法。
- 無料で財務データが取得できる
- 過去5年分の財務データが取得できる
- Google Colab を使えば5分で導入・実行できる(この記事のコードをコピペするだけ)
- 全上場銘柄の財務データを取得する
この記事では触れませんが、ガッツリ活用すると、過去5年分のすべての上場企業の財務データを集めることができます。
ツイートを見ると、実際に5分で実行までできているようです(よかった)。
Twitterでも紹介していただいています
財務データの提供も行っています
2021年11月1日時点の財務データをダウンロードすることもできます。
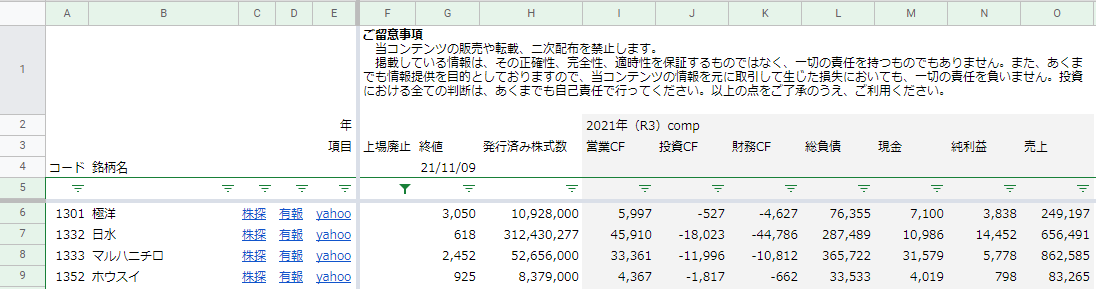
- 2009~2021年のデータ
- 各キャッシュフローと総負債、現金、純利益、売上
追記・修正
2021年11月13日 追記
財務データの提供を追加。
2020年6月10日 大幅な修正
記事全体を大幅に修正。コードを最適化した最新のものに差し替え。
2019年1月25日 追記
「ファイルのダウンロードがうまくいかない場合」を追記。
2019年1月24日 追記・修正
一部、追記とコードの修正を行った。
EDINETとXRBLとは
前提知識のメモ。
有価証券報告書
金融商品取引法で規定されている、事業年度ごとに作成する企業内容の外部への開示資料である。略して有報(ゆうほう)と呼ばれることもある。
引用元: 有価証券報告書 - Wikipedia
EDINET
- Electronic Disclosure for Investor’s NETworkの略
- 金融庁により運用されている「金融商品取引法に基づく有価証券報告書等の開示書類に関する電子開示システム」
- 企業は電子データ(XBRLファイル)による「財務諸表」提出の義務がある
- トップページ -EDINET
- 7203:トヨタ自動車株式会社 -EDINET
- PDFを開くと有価証券報告書を確認することができる

XBRL
- eXtensible Business Reporting Languageの略
- データの表現方法のひとつ(あくまでもイメージだが、図のような構成になっている)
- 財務諸表データの表現用途に特化したXMLベースの言語(HTMLみたいなもの)
- 米国の EDGAR(企業情報開示システム)でも採用されている
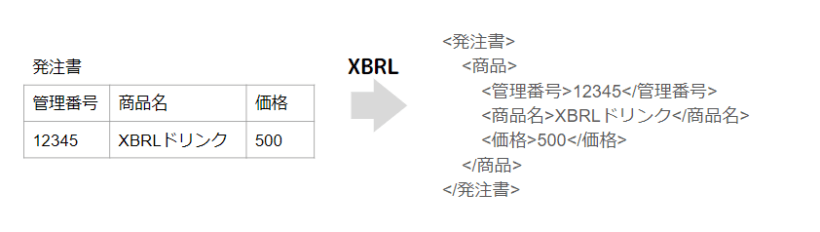
上場企業の財務諸表がEDINETにあり、XBRLファイルで保存されている。掲載されているのは決算時点のデータ。
XBRLからデータを取得する
この記事のコードをGoogle Colabで上から順番に実行していくと、EDINETのデータを取得することができる。
Googleドライブをマウントしておく
対象の銘柄が多いと、処理の時間が長くかかる。また、過程で生成されるeggs.csvを保存しておくと一度取得した全データの保存が効く。すべてのコードについて保存先を指定することができ、PROJECT_NAMEで指定するフォルダに格納されるように構成している。
from google.colab import drive
drive.mount('/content/drive')
PROJECT_NAME = 'EDINETScraping'
BASE_DIR = f'/content/drive/My Drive/Colab Notebooks/data/{ PROJECT_NAME }/'
import os
os.makedirs( BASE_DIR ,exist_ok=True )① EDINETAPIからURLを取得
EDINETのAPIから必要なXBRLファイルのURLを取得し、dat_download.csvというURL一覧のファイルを作成する。
以下のCell-2 Cell-3をそのまま実行するとdat_download_200601_200602.csvというファイルが作成される。
import csv ,time ,re ,os ,json ,requests
from tqdm import tqdm
from datetime import datetime ,timedelta
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
class catcher() :
def __init__( self ,since ,until ,base_dir=None ,wait_time=2 ) :
self.csv_tag = [ 'id' ,'title' ,'url' ,'code' ,'update' ]
self.encode_type = 'utf-8'
self.wait_time = wait_time
self.base_url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents'
self.out_of_since = False
self.since = since
self.until = until
self.file_info_str = since.strftime( '_%y%m%d_' ) + until.strftime( '%y%m%d' )
self.file_name = f'dat_download{ self.file_info_str }.csv'
self.base_path = f'{ os.getcwd() if base_dir==None else base_dir }'
def __get_link_info_str( self ,datetime ) :
str_datetime = datetime.strftime( '%Y-%m-%d' )
params = { "date" : str_datetime ,"type" : 2 }
count ,retry = 0 ,3
while True:
try :
response = requests.get( f'{ self.base_url }.json' ,params=params ,verify=False )
return response.text
except Exception :
print( f'{str_datetime} のアクセスに失敗しました。[ {count} ]' )
if count < retry :
count += 1
time.sleep( 3 )
continue
else : raise
def __parse_json( self ,string ) :
res_dict = json.loads( string )
return res_dict["results"]
def __get_link( self ,target_list ) :
edinet_dict = {}
for target_dict in target_list :
title = f'{ target_dict["filerName"] } { target_dict["docDescription"] }'
if not self.__is_yuho( title ) : continue
docID = target_dict["docID"]
url = f'{ self.base_url }/{ docID }'
edinet_code = target_dict['edinetCode']
updated = target_dict['submitDateTime']
edinet_dict[ docID ] = { 'id':docID ,'title':title ,'url':url ,'code':edinet_code ,'update':updated }
return edinet_dict
def __is_yuho( self ,title ) :
if all( ( s in str( title ) ) for s in [ '有価証券報告書' ,'株式会社' ] ) and '受益証券' not in str( title ) :
return True
return False
def __dump_file( self ,result_dict ) :
with open( os.path.join( self.base_path ,self.file_name ) ,'w' ,encoding=self.encode_type ) as of :
writer = csv.DictWriter( of ,self.csv_tag ,lineterminator='\n' )
writer.writeheader()
for key in result_dict : writer.writerow( result_dict[ key ] )
def create_xbrl_url_csv( self ) :
print( f'since: { self.since.strftime( "%Y-%m-%d" ) } ,until: { self.until.strftime( "%Y-%m-%d" ) } ({ self.file_info_str })' )
target_date ,result_dict = self.since ,{}
while True :
print( f'date { target_date.strftime( "%Y-%m-%d" ) }, loading...' )
response_string = self.__get_link_info_str( target_date )
target_list = self.__parse_json( response_string )
info_dict = self.__get_link( target_list )
result_dict.update( info_dict )
time.sleep( self.wait_time )
target_date = target_date + timedelta( days=1 )
if target_date > self.until : break
self.__dump_file( result_dict )
print( 'complete a download!!' )
def edinet_operator( since ,until ,base_dir=None ) :
edinet_catcher = catcher( since ,until ,base_dir )
edinet_catcher.create_xbrl_url_csv()from datetime import datetime
since = datetime.strptime('2020-06-01' ,'%Y-%m-%d')
until = datetime.strptime('2020-06-02' ,'%Y-%m-%d')
edinet_operator( since ,until ,base_dir=BASE_DIR )以下は、完成品のサンプル。実際はGoogleシートではなくCSVファイル。
② ZIPファイルをDLして全ての財務データをCSVに保存
まずは、Google Colabに入っていないモジュール(python-xbrl)をインストール。
!pip install python-xbrl続いてCell-5 Cell-6を実行するとeggs_200601_200602.csvというファイルが作成される。これはCell-3までに作成したURL一覧からXBRLファイルをダウンロードし、分析に使えるすべてのデータをCSVにまとめたもの。
import os ,re ,csv ,io ,time ,requests
import pandas as pd
from tqdm import tqdm
from zipfile import ZipFile
from xbrl import XBRLParser
default_tag = ['file_nm','element_id','amount']
custom_tag = ['unit_ref','decimals','contextref']
encode_type = 'utf-8'
class downloader() :
def __init__( self ,wait_time=1 ,base_dir=None ) :
self.wait_time = wait_time
self.base_path = f'{ os.getcwd() if base_dir==None else base_dir }'
def __make_directory( self ,dir_path ) :
os.makedirs( dir_path ,exist_ok=True )
def __download_all_xbrl_files( self ,info_df ) :
counter ,mp_dict = 0 ,{}
for index ,row in info_df.iterrows() :
mp_dict[ counter ] = row.to_dict()
counter += 1
self.__download_xbrl_file( mp_dict )
def __download_xbrl_file( self ,info_dicts ) :
for no in tqdm( info_dicts ) :
info_dict = info_dicts[ no ]
company_path = f'{ self.directory_path }{ info_dict["code"] }/'
ir_path = f'{ company_path }{ info_dict["id"] }'
self.__make_directory( company_path )
self.__make_directory( ir_path )
self.__download_and_unzip( info_dict['url'] ,ir_path )
no += 1
def __download_and_unzip( self ,url ,dir_path ) :
count ,retry = 0 ,3
while True:
r = requests.get( url ,params={ 'type' : 1 } )
time.sleep( self.wait_time )
if r.status_code == 200 :
z = ZipFile( io.BytesIO( r.content ) )
z.extractall( dir_path )
break
else :
print( f'download failed [{ count }]_{ url }' )
if count < retry :
count += 1
continue
else : raise
def download( self ,list_dat_csv ) :
for dat_csv in list_dat_csv :
info_df = pd.read_csv( os.path.join( self.base_path ,dat_csv ) ,parse_dates=['update'] )
if len( info_df ) > 0 :
self.directory_path = f'{ os.getcwd() }/xbrl_files_{ dat_csv.replace( ".csv" ,"" ).replace( "dat_download_" ,"" ) }/'
self.__make_directory( self.directory_path )
self.__download_all_xbrl_files( info_df )
print( 'complete a download!!' )
class XbrlParser( XBRLParser ) :
def __init__( self ,xbrl_filepath ) :
self.xbrl_filepath = xbrl_filepath
def parse_xbrl( self ):
# parse xbrl file
with open( self.xbrl_filepath ,'r' ,encoding='utf-8' ) as of:
xbrl = XBRLParser.parse( of )
result_dicts = {}
i = 0
name_space = 'jp*'
for node in xbrl.find_all( name=re.compile(name_space+':*') ):
if self.ignore_pattern( node ) : continue
row_dict = {}
row_dict['file_nm'] = self.xbrl_filepath.rsplit( os.sep ,1 )[1]
row_dict['element_id'] = node.name
row_dict['amount'] = node.string
for tag in custom_tag:
row_dict[tag] = self.get_attrib_value( node ,tag )
result_dicts[i] = row_dict
i += 1
return result_dicts
def ignore_pattern( self ,node ):
if 'xsi:nil' in node.attrs:
if node.attrs['xsi:nil']=='true' : return True
if not isinstance( node.string ,str ) : return True #結果が空の場合は対象外にする
if str( node.string ).find(u'\n') > -1 : return True #結果が空の場合は対象外にする
if u'textblock' in str( node.name ) : return True #結果が空の場合は対象外にする
return False
def get_attrib_value( self, node, attrib ):
if attrib in node.attrs.keys() : return node.attrs[ attrib ]
else : return None
class parse_operator() :
def __init__( self ,list_dat_csv ,base_dir=None ) :
self.list_dat_csv = list_dat_csv
self.base_path = f'{ os.getcwd() if base_dir==None else base_dir }'
def __fild_all_files( self ):
result = []
for root, dirs, files in os.walk( self.search_path ) :
for file in files:
if not self.__is_xbrl_file( root ,file ) : continue
result.append( os.path.join( root ,file ) )
return result
def __is_xbrl_file( self ,root_path ,file_name ) :
if not file_name.endswith('.xbrl') : return False #xbrlファイルでなければ対象外
if u'AuditDoc' in str( root_path ) : return False #AuditDocは対象外
if 'xbrl_files_'+self.str_period in str( root_path ) : return True
def __dump_file( self ,writer ,dicts_info ) :
i = 0
while i < len( dicts_info ) :
row_dict = dicts_info[i]
writer.writerow( row_dict )
i += 1
def xbrl_to_csv( self ) :
for dat_csv in self.list_dat_csv :
self.str_period = dat_csv.replace( ".csv" ,"" ).replace( "dat_download_" ,"" )
eggs_file = f'eggs_{ self.str_period }.csv'
self.search_path = f'{ os.getcwd() }/xbrl_files_{ self.str_period }/'
with open( os.path.join( self.base_path ,eggs_file ) ,'w' ,encoding=encode_type ) as of :
resultCsvWriter = csv.DictWriter( of ,default_tag + custom_tag ,lineterminator='\n' )
resultCsvWriter.writeheader()
list_xbrl_files = self.__fild_all_files()
for xbrl_file in tqdm( list_xbrl_files ) :
xp = XbrlParser( xbrl_file )
dicts_info = xp.parse_xbrl()
self.__dump_file( resultCsvWriter ,dicts_info )
print( 'completed conversions!!' )
def xbrl_to_csv_operator( list_dat_csv ,base_dir=None ) :
xbrl_downloader = downloader( base_dir=base_dir )
xbrl_downloader.download( list_dat_csv )
xbrl_parse_operator = parse_operator( list_dat_csv ,base_dir=base_dir )
xbrl_parse_operator.xbrl_to_csv()dat_list = [ 'dat_download_200601_200602.csv' ]
xbrl_to_csv_operator( dat_list ,base_dir=BASE_DIR )ここで指定するdat_listは、存在するものである必要がある。eggs.csvは指定した期間の全企業の全財務データが記録される。このデータを保存しておくと繰り返し使えて便利。完成品のサンプルは、以下のGoogleシートを参照(実際はCSV)。

銘柄リストを手動でアップロード
上場している企業のデータだけ取得するために、「EDINETのコード」と「証券コード」を付け合わせる必要がある。EDINETのページで公開されているEdinetcodeDlInfo.csvというファイルを用いる。これは自動取得がむずかしいため、手動でダウンロードする必要がある。
EdinetcodeDlInfo.csvを入手
EDINETにアクセス。

トップページ下部の「EDINETタクソノミ及びコードリスト」をクリック。

リンク先のページ下部の「EDINETコードリスト」をクリックしてダウンロード。

Google ColabにEdinetcodeDlInfo.csvをアップロード
取得したEdinetcodeDlInfo.csv をCell-1で指定しているGoogleドライブのフォルダ(マイドライブ/Colab Notebooks/data/EDINETScraping)にアップロードする。ファイル名はそのまま。
EdinetcodeDlInfo.csvは以下のような内容。実際はCSVファイル。
③ 全財務データのCSVから必要なデータを抽出
次にCell-7を実行する。
import re
import pandas as pd
from tqdm import tqdm
def get_dict_edinet_codes( DIR ,index='証券コード' ) :
import codecs
file_path = f'{DIR}EdinetcodeDlInfo.csv'
with codecs.open( file_path, "r", "Shift-JIS", "ignore" ) as file :
df = pd.read_csv( file ,skiprows=[0] ,usecols=['EDINETコード','提出者名','証券コード','提出者業種'] )
df = df.loc[ df['証券コード'] > 0 ,: ]
df['証券コード'] = df['証券コード'] / 10
df['証券コード'] = df['証券コード'].astype( int )
result = df.set_index( index ).T.to_dict()
print( f'対象(EDINET): { len( result ) }銘柄' )
return result
def make_element_ids_csv( egg_file_name ,base_dir=None ) :
base_path = f'{ os.getcwd() if base_dir==None else base_dir }'
result_file_name = f'element_ids ( { egg_file_name } ).csv'
df_egg = pd.read_csv( os.path.join( base_path ,egg_file_name ) ).drop_duplicates()
df_egg.loc[ : ,'element_id' ].drop_duplicates().to_csv( os.path.join( base_path ,result_file_name ) )
def make_sample_data_csv( egg_file_name ,edinet_code ,base_dir=None ) :
base_path = f'{ os.getcwd() if base_dir==None else base_dir }'
result_file_name = f'sample_data ( { egg_file_name } { edinet_code } ).csv'
df_egg = pd.read_csv( os.path.join( base_path ,egg_file_name ) ).drop_duplicates()
check1 = df_egg[ ( df_egg['file_nm'].str.contains( edinet_code ) ) ]
if len( check1 ) > 0 : check1.to_csv( os.path.join( base_path ,result_file_name ) )
else : print( f'{ edinet_code }のデータはありませんでした' )
class eggs_operator() :
def __init__( self ,list_eggs ,dict_codes ,dict_cols ,result_file_name='com_indices.csv' ,base_dir=None ) :
self.base_path = f'{ os.getcwd() if base_dir==None else base_dir }'
self.result_file_name = result_file_name
self.list_df_eggs = [ pd.read_csv( os.path.join( self.base_path ,egg_file_name ) ).drop_duplicates() for egg_file_name in list_eggs ]
self.dict_codes = dict_codes
self.dict_cols = dict_cols
def __get_element( self ,df ,col ) :
element_ids = self.dict_cols[ col ]['element_id']
if col in [ '会社名' ,'提出書類' ,'提出日' ,'年度開始日' ,'年度終了日' ] :
check1 = df[ df['element_id'].str.contains( element_ids[0].lower() ) ]
if len( check1 )==1 : return check1['amount'].values[0]
else : return 0
else :
contextref = self.dict_cols[col]['contextref']
for element_id in element_ids :
check1 = df[ df['element_id'].str.contains( element_id.lower() ) ]
check2 = check1[ check1['contextref']==contextref ].copy()
if len( check2 )==1 :
return check2['amount'].values[0]
elif len( check2 ) > 1 :
check2['str_len'] = check2['element_id'].apply( lambda x: len( str(x) ) )
return check2.loc[ check2['str_len']==check2['str_len'].min() ,'amount' ].values[0]
for element_id in element_ids :
check1 = df[ df['element_id'].str.contains( element_id.lower() ) ]
check2 = check1[ check1['contextref']==f'{ contextref }_NonConsolidatedMember' ].copy()
if len( check2 )==1 :
return check2['amount'].values[0]
elif len( check2 ) > 1 :
check2['str_len'] = check2['element_id'].apply( lambda x: len( str(x) ) )
return check2.loc[ check2['str_len']==check2['str_len'].min() ,'amount' ].values[0]
return 0
def get_elements( self ) :
com_indices = pd.DataFrame()
for df_eggs in self.list_df_eggs :
file_nms = df_eggs[ df_eggs['element_id']=='jpcrp_cor:companynamecoverpage' ].drop_duplicates()['file_nm'].values
for file_nm in tqdm( file_nms ) :
edinet_code = re.search( r'E[0-9]{5}' ,file_nm ).group(0)
if not edinet_code in self.dict_codes : continue
df_target = df_eggs[ df_eggs['file_nm']==file_nm ]
data = { col : self.__get_element( df_target ,col ) for col in self.dict_cols }
data['証券コード'] = self.dict_codes[ edinet_code ]['証券コード']
data['業種'] = self.dict_codes[ edinet_code ]['提出者業種']
data['訂正'] = 1 if '訂正' in data['提出書類'] else 0
data['file_nm'] = file_nm
raw = pd.DataFrame( data ,index=[ edinet_code ] )
com_indices = pd.concat( [ com_indices ,raw ] )
com_indices.to_csv( os.path.join( self.base_path ,self.result_file_name ) )Cell-7にはメイン処理の関数以外に以下が含まれている。
make_element_ids_csv( egg_file_name ,base_dir )
eggs.csvに含まれるすべてのelement_id(XBRLのタグ)の一覧を作成する
make_sample_data_csv( egg_file_name ,edinet_code ,base_dir )
- EDINETコード(企業固有の番号)をもとに、特定の企業の全データの一覧を作成する
get_dict_edinet_codes( BASE_DIR ,'EDINETコード' )
- EDINETコードリストを読み込む関数
続いて、Cell-8を実行して「EDINETコードと証券コードのリスト」を読み込む。
dict_codes = get_dict_edinet_codes( BASE_DIR ,'EDINETコード' )Cell-9ではファイル名と必要なデータの指定する。(他の財務データを指定する方法は後述する)
##
# 読み込みの設定
#
list_eggs = [ 'eggs_200601_200602.csv' ]
result_file_name = 'com_indices_200601_200602.csv'
#(複数あるものは上のものほど優先される)
dict_cols = {
'会社名' : { 'element_id' : ['companynamecoverpage'] }
, '提出書類' : { 'element_id' : ['documenttitlecoverpage'] }
, '提出日' : { 'element_id' : ['filingdatecoverpage'] }
, '年度開始日' : { 'element_id' : ['currentfiscalyearstartdatedei'] }
, '年度終了日' : { 'element_id' : ['currentfiscalyearenddatedei'] }
#---ここまで必須---
#以下は 'contextref' が必須
, '発行済み株式数' : { 'element_id' : ['totalnumberofissuedsharessummaryofbusinessresults'
,'totalnumberofissuedsharescommonstocksummaryofbusinessresults'
,'totalnumberofissuedshares']
,'contextref' : 'CurrentYearInstant' }
, '営業CF' : { 'element_id' : ['netcashprovidedbyusedinoperatingactivitiessummaryofbusinessresults'
,'cashflowsfromusedinoperatingactivitiesifrssummaryofbusinessresults'
,'CashFlowsFromUsedInOperatingActivitiesUSGAAPSummaryOfBusinessResults']
,'contextref' : 'CurrentYearDuration' }
, '財務CF' : { 'element_id' : ['netcashprovidedbyusedinfinancingactivitiessummaryofbusinessresults'
,'cashflowsfromusedinfinancingactivitiesifrssummaryofbusinessresults'
,'CashFlowsFromUsedInFinancingActivitiesUSGAAPSummaryOfBusinessResults']
,'contextref' : 'CurrentYearDuration' }
, '投資CF' : { 'element_id' : ['netcashprovidedbyusedininvestingactivitiessummaryofbusinessresults'
,'cashflowsfromusedininvestingactivitiesifrssummaryofbusinessresults'
,'CashFlowsFromUsedInInvestingActivitiesUSGAAPSummaryOfBusinessResults']
,'contextref' : 'CurrentYearDuration' }
, '純利益' : { 'element_id' : ['profitlossattributabletoownersofparentsummaryofbusinessresults'
,'ProfitLossAttributableToOwnersOfParentIFRSSummaryOfBusinessResults'
,'NetIncomeLossAttributableToOwnersOfParentUSGAAPSummaryOfBusinessResults'
,'netincomelosssummaryofbusinessresults']
,'contextref' : 'CurrentYearDuration' }
, '売上高' : { 'element_id' : ['netsalessummaryofbusinessresults'
,'NetSalesIFRSSummaryOfBusinessResults'
,'RevenuesUSGAAPSummaryOfBusinessResults'
,'operatingrevenue1summaryofbusinessresults'
,'revenueifrssummaryofbusinessresults'
,'netoperatingrevenuesummaryofbusinessresults'
,'businessrevenuesummaryofbusinessresults']
,'contextref' : 'CurrentYearDuration' }
, 'BS 現金預金' : { 'element_id' : ['cashanddeposits']
,'contextref' : 'CurrentYearInstant' }
, 'BS 負債合計' : { 'element_id' : ['liabilities']
,'contextref' : 'CurrentYearInstant' }
}Cell-10で実行すると指定した財務データが抽出され、com_indices_200601_200602.csvというファイルが作成される。内容は次の通り。実際はCSVファイル。
eggs_operator = eggs_operator( list_eggs ,dict_codes ,dict_cols ,result_file_name=result_file_name ,base_dir=BASE_DIR )
eggs_operator.get_elements()
大幅な変更を加えているが、ここまでのコードは以下の記事を参考に作成した。
他の財務データを抽出
ここまでのコードに含まれている財務データでは足りない場合、抽出したい財務データの設定を加える必要がある。ここからは、抽出する財務データを増やす方法について解説する。
XBRLを理解する

XBRLは、ひとつのデータをこのように表現している。上記の中で、jpcrp_cor:RevenuesUSGAAPSummaryOfBusinessResultsの箇所のことを要素(element)と呼ぶ。この記事では、コードを含めてelement_idと表現している。
このelement_idは、データの項目を表していて、例えば、

SummaryOfBussinessResultsは、有価証券報告書の冒頭に記載されている経営指標の表を指している。
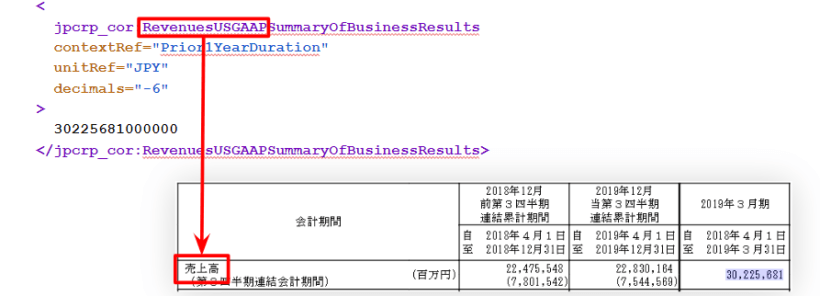
さらに、Revenuesは「売上」を表し、USGAAPは「米国の会計基準」を表している。
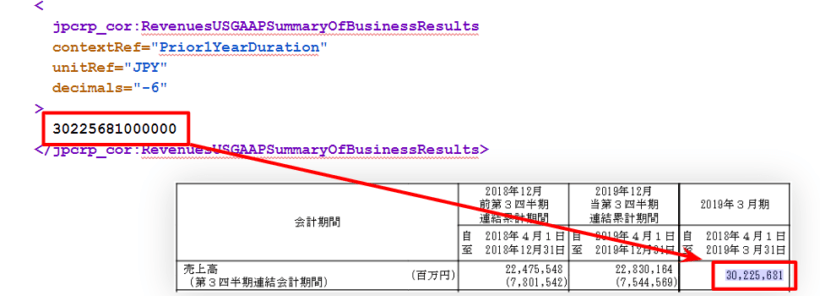
そして、要素に挟まれた数字はその項目(財務データ)の数値を表しており、この記事の中ではAmountと表現している。
contextRef unitRef decimalsは属性(attribute)と呼ばれるもの。
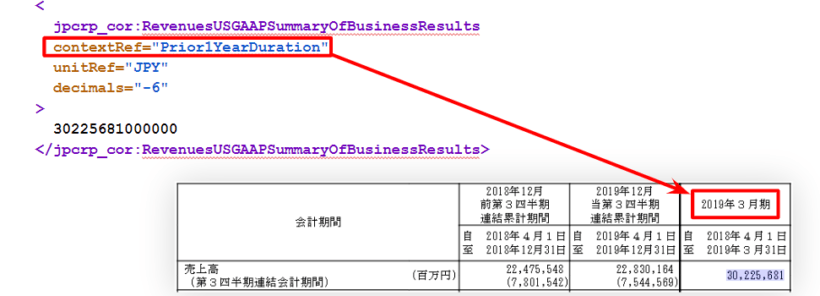
contextRefは「いつ時点」の財務データであるかを表し、
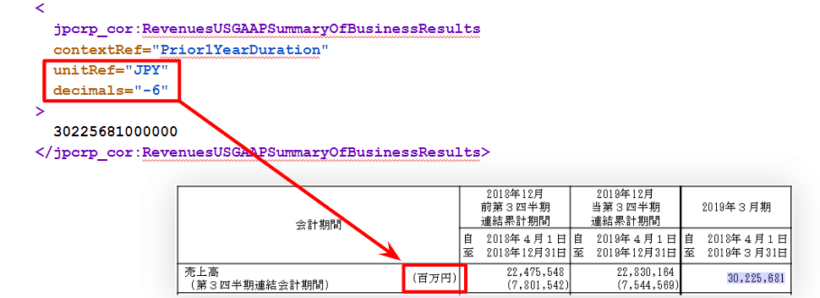
unitRef decimalsの2つで「単位」を表している。
同じ財務データを表す要素であっても、業種や会計基準で様々
XBRLのスクレイピングでもっともやっかいなのは、この点であると思う。要素名は、以下の情報の組み合わせで決まる。「売上高」は名称がとくに多い例であるが、このように複数の名称が確認できるケースは非常によくある。
会計基準
- 表記なし → 日本基準
- IFRS → 国際財務報告基準
- USGAAP → 米国基準
�例)「売上高」の場合
- NetSales
- Revenues
- OperatingRevenue1
- NetOperatingRevenue
- BusinessRevenue
必要な財務データのelement_idを特定する
ここで役に立つのがCell-7の以下の関数である。
make_element_ids_csv( egg_file_name ,base_dir )
eggs.csvに含まれるすべてのelement_id(XBRLのタグ)の一覧を作成する
make_sample_data_csv( egg_file_name ,edinet_code ,base_dir )
- EDINETコード(企業固有の番号)をもとに、特定の企業の全データの一覧を作成する
まず、EDINETで要素名(element_id)を特定したい企業および決算の有価証券報告書を開き、特定したい「財務データの数値」を控えておく。同時に、dat_download.csvやEdinetcodeDlInfo.csvを元に、特定したい企業の「EDINETコード」を控える。
続いて、sample_code_listに、控えておいた「EDINETコード」と対象となるeggs.csvを入力し、Cell-11を実行する。
sample_code_list = ['E02925']
for edinet_code in sample_code_list :
make_sample_data_csv( 'eggs_200601_200602.csv' ,edinet_code ,base_dir=BASE_DIR )eggs.csvに指定した「EDINETコード」の情報が含まれていれば、次のようなファイルが作成される。
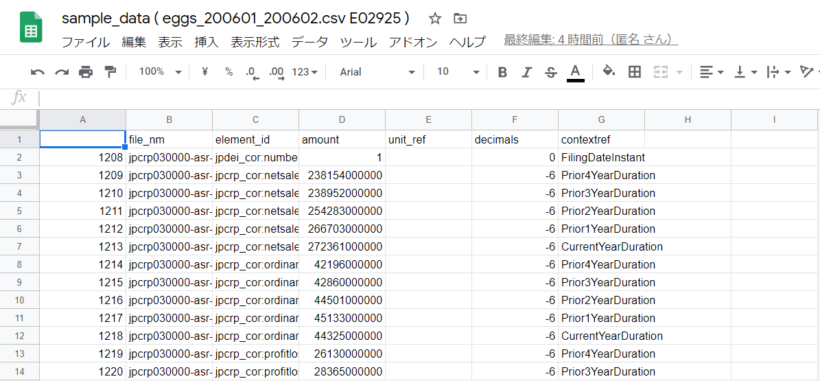
このCSVを開き、控えておいた「財務データの数値」で検索すると、要素名(element_id)を特定することができる。同時にcontextRefも特定することができる。特定した要素名(element_id)とcontextRefをCell-9に追記することで、取得する財務データを増やすことができる。
財務データによっては一度では上手くいかないので、複数回、Cell-10のコードでcom_indices.csvを作成し、虫食いを埋めていく作業になる。
Cell-12のコードを実行すると、指定したeggs.csvに含まれる全ての要素名(element_id)を抽出したCSVを作成する。必要に応じて使用する。
make_element_ids_csv( 'eggs_200601_200602.csv' ,base_dir=BASE_DIR )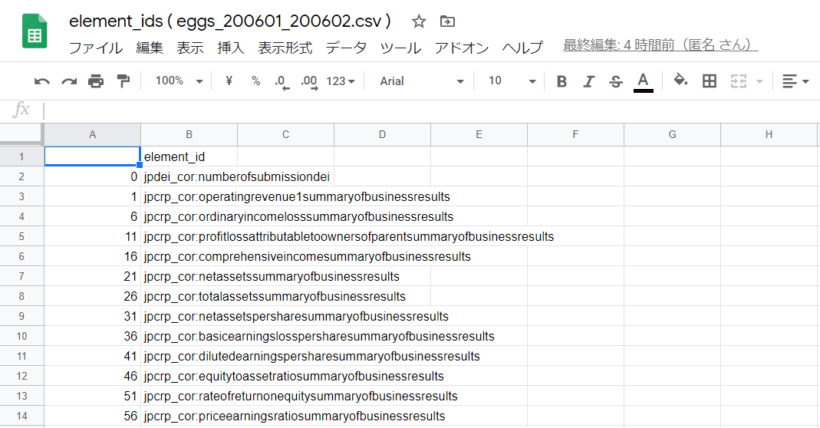
ファイルのダウンロードがうまくいかない場合
ファイルのダウンロードでエラーが発生し、対処した。メモ。
chrome://settings/content/cookiesにアクセスし、「サードパーティの Cookie をブロックする」が無効になっていることを確認。

「許可」にcolab.research.google.comを追加。

財務データと確認用のGoogle Colab
- 記事に使用したGoogle Colab
- 上場銘柄の財務データ(2009~2021年、キャッシュフローと総負債、現金、純利益、売上)
は「Google Colab サンプル集」に置いています。

まだ登録されていない方は以下からご登録いただけます。
開発を承っています
- Pineスクリプト(インジケーターやストラテジー)
- Google Apps Script
- Python
- MQL4
などの開発を承っています。とくに投資関連が得意です。過去の事例は「実績ページ(不定期更新)」でご確認ください。ご相談は「お問い合わせ」からお願いします。


- 記事をシェア